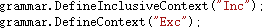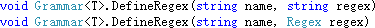|
在之前的六篇文章中,我比较详细的介绍了与词法分析器相关的算法。它们都比较关注于实现的细节,感觉上可能比较凌乱,本篇就从整体上介绍一下如何定义词法分析器,以及如何实现自己的词法分析器。 第二节完整的介绍了如何定义词法分析器,可以当作一个词法分析器使用指南。如果不关心词法分析器的具体实现的话,可以只看第二节。 首先需要说明一下我对类库做的一些修改。词法分析部分的接口,与当初写《C# 词法分析器》系列时相比,已经发生了不小的改变,有必要做一下说明。 词法单元(token)最初的定义是一个 Token 结构,使用一个 int 属性作为词法单元的标识符,这也是很多词法分析器的通用做法。 但后来做语法分析的时候,感觉这样非常不方便。因为目前还不支持从定义文件生成词法分析器代码,只能在程序里面定义词法分析器。而 int 本身是不具有语义的,作为词法单元的标识符来使用,不但不方便还容易出错。 后来尝试过使用字符串作为标识符,虽然解决了语义的问题,但仍然容易出错,实现上也会复杂些(需要保存字符串字典)。 而既简单,又具有语义的解决方案,就是使用枚举了。枚举名称提供了语义,枚举值又可以转换为整数,而且还能够提供编译期检查,完全避免了拼写错误,所以现在的词法单元便定义为TokenT 类,与之相关的很多类也同样带上了泛型参数 T。 之前对词法分析器上下文的切换,可以使用上下文的索引、标签或 LexerContext 实例本身。但现在只能够通过标签进行切换,这样实现起来更简单些,使用上也不会受到过多影响。 原先 LexerRule 类中对 DFA 的表示有些简单粗暴,对于不了解具体实现的人来说,很难理解 DFA 的表示。现在重新规划了LexerRuleT 类中的接口,理解起来会更容易些。 这一节是 Cyjb.Compilers 类库中词法分析器的使用指南,包含了完整的文档、实例以及相关注意事项。类库的源码可以从Cyjb.Compilers 项目找到,类库文档请参见wiki。 前面说到,目前是使用枚举类型作为词法单元的标识符,这个枚举类型中的字段可以任意定义,没有任何限制。不过,为了方便之后的语法分析部分,特别要求枚举值必须是从 0 开始的整数,枚举值最好是连续的,因为不连续的枚举值会导致语法分析部分浪费更多的空间。
词法分析器的上下文,可以用来控制规则是否生效。上下文有两种类型:包含型或者排除型。 使用以下的方法来分别定义排除型和包含型的词法分析器上下文,label 参数即为上下文的标签:
默认的词法分析器上下文是 Initial,通过该标签可以切换到默认的上下文中。需要特别注意的是,由于实现上的原因,上下文必须先于所有终结符定义。 例如,以下的代码定义了一个包含型上下文 Inc,以及一个排除型上下文 Exc。
正则表达式可以通过ilers.RegularExpressions.Regex 类的相关方法构造得到,也可以直接使用表示正则表达式的字符串,相关定义的规则可以参考《C# 词法分析器(三)正则表达式》。 注意,这里定义的正则表达式仅仅用于简化终结符定义,方便重复使用一些通用或复杂的正则表达式,并没有其它的作用。这里定义的正则表达式也不可以包含向前看符号(/)、行首限定符(^)、行尾限定符($)或者上下文(context)。 |